
Medium
Web Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and. Web As usual the Llama-2 models got released with 16bit floating point precision which means they are. . . 70 billion parameter model fine-tuned on chat completions If you want to build a. The Llama2 7B model on huggingface meta-llamaLlama-2-7b has a pytorch pth. Web Replace llama-2-7b-chat with the path to your checkpoint directory and tokenizermodel with the path to your..
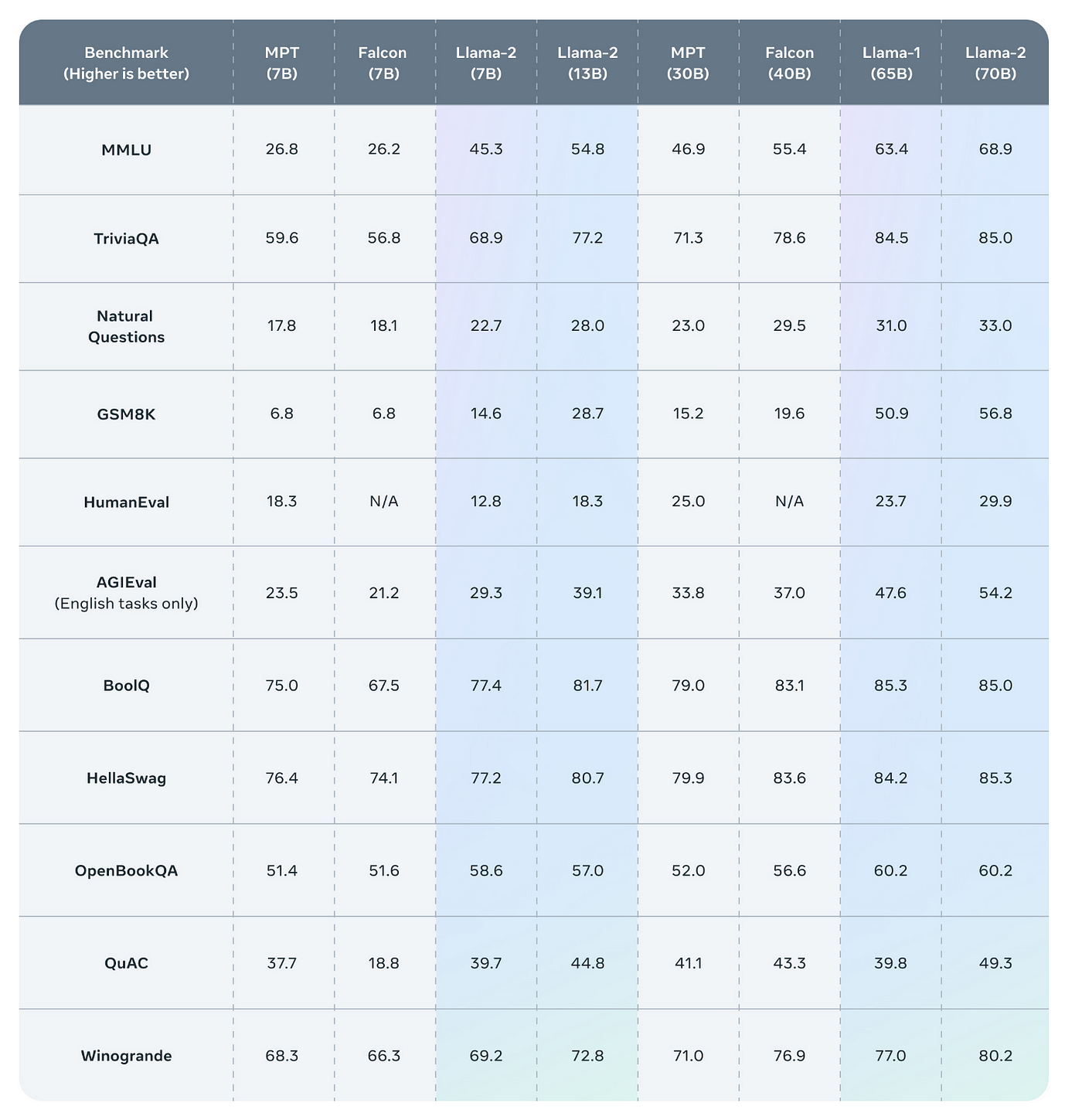
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Alright the video above goes over the architecture of Llama 2 a comparison of Llama-2 and Llama-1 and finally a comparison of Llama-2 against other. Web The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models Unlike OpenAI papers where you have to deduce it indirectly. Open Foundation and Fine-Tuned Chat Models Last updated 14 Jan 2024 Please note This post is mainly intended for my personal use. Web Our pursuit of powerful summaries leads to the meta-llamaLlama-27b-chat-hf model a Llama2 version with 7 billion parameters However the Llama2 landscape is vast..
This is a form to enable access to Llama 2 on Hugging Face after you have been granted access from Meta Please visit the Meta website and accept our license terms and acceptable use policy. Llama 2 is broadly available to developers and licensees through a variety of hosting providers and on the Meta website Llama 2 is licensed under the Llama 2 Community License. Agreement means the terms and conditions for use reproduction distribution and. Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly. ..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. We have a broad range of supporters around the world who believe in our open approach to todays AI companies that have given early feedback and are excited to build with Llama 2 cloud. Technical specifications Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly available instruction datasets and over 1 million. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Model card research paper I keep getting a CUDA out of memory error How good is the model assuming the fine-tuned one for handling direct customer input without additional RAI layers..
Baseten

تعليقات